









































































































by Boladale Erogbogbo (’23) | March 29, 2021
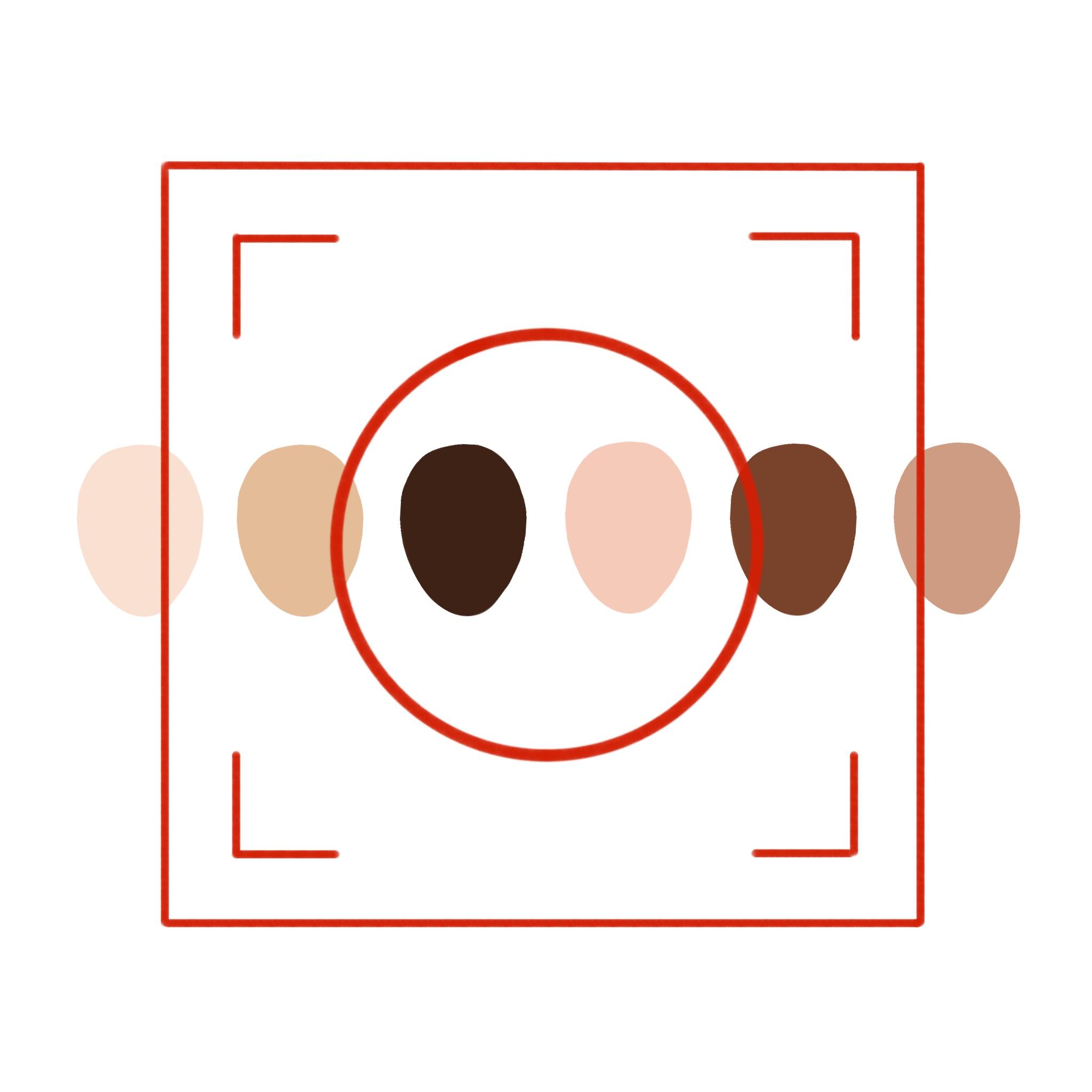
Artificial intelligence (AI) technology has the potential to simplify our increasingly complex world. AI can function as a valuable tool in processing information that humans alone are unable to process by utilizing engineered algorithms and vast quantities of real-world data. However, as AI continues to improve in efficiency and complexity, it still manages to maintain one human characteristic: bias. Just as humans are subject to inherent bias, the machines they manufacture are too—whether it be racial prejudice or general preference.
Machines are products of the information humans feed them. Like us, they function and execute tasks based on given data from their environment. Using this training data, software engineers can mimic real-world scenarios, manage social media platforms, and, in some cases, predict the occurrence of violent activity. All in all, there is a significant benefit to the implementation of AI into public systems. However, a problem arises either when data is flawed or an exclusive demographic of engineers create said products.
Many U.S. courts, for instance, have approved of a program called COMPAS to identify the possibility of reoffense for convicts from a variety of backgrounds. COMPAS uses arrest records, postcodes, social affiliations, and income to rank this possibility on a scale of one to ten. However, a 2016 report by ProPublica uncovered the racial bias of this program, stating that COMPAS found black defendants to be almost twice as likely (45% to 24%) to re-offend as white ones, despite having fewer and/or less severe initial offenses. In another case, another AI program known as PredPol was used by the Oakland police. Using recent crime and arrest data with historical drug records, the department attempted to create a simulation of possible “crime hotspots” that would simplify patrol routes and minimize criminal activity. In the end, however, PredPol produced an inaccurate distribution of crime activity that showed bias towards black and brown neighborhoods, as shown by a verified model of drug use based on national statistics.
The pressing concern of the effectiveness of AI technology isn’t just limited to identifying crime. It’s a pandemic that permeates many of the technological aspects of our society today. Studies show that facial recognition models often fail to recognize Black, Middle Eastern, or Latinx people more often than those with lighter skin. And some previously developed Facebook algorithms were 50% more likely to disable black user accounts than white user accounts.
But how did these problems arise? The answer lies in the data and the people who generated them. All of these programs rely on unreliable records of human information. In the case of COMPAS, the program assumed a rate of reoffense based on known discrepancies between races. It falsely correlated individual crime tendencies with data heavily influenced by human prejudice. In the case of PredPol, bias is prevalent in the possibility of creating a “feedback loop.” Had the Oakland police department acted on PredPol’s simulation, it would create a problematic recurring system of arrests in the “hotspots.” Increased patrol in those areas would lead to an increased rate of arrest and incite a greater deployment of officers creating a “feedback loop” based on assumed crime statistics. Lastly, in the case of facial recognition and social media, U.S. software engineering demographics are largely dominated by male, East Asian, and White Americans. The lack of diversity in production of AI technology denies these programs the opportunity to accurately cater to the variety of people they will serve in the real world. Furthermore, it limits the versatility of such programs and denies companies a valuable user base which may end up hurting more than helping in the long run.
